

Rethinking Real-Time AI Interactions
How continuous multimodal models can replace turn-based conversation systems

Over the past year, real-time AI interaction has quietly crossed from novelty into something approaching normalcy. Whether you’ve had a live voice conversation with Gemini Live, or OpenAI live responding mid-sentence, or simply seen the clips circulating online, the general shape of it is familiar by now. You speak, the AI listens, and it speaks back. On the surface, it feels remarkably close to talking to another person.
But spend enough time with these systems and a particular kind of friction starts to surface. You pause mid-sentence to collect your thoughts, and the AI jumps in. Or you finish speaking, and there’s that half-second of dead air, the system “thinking” before a response arrives. These moments are small, but they accumulate into something that never quite lets you forget you’re talking to a machine.
Last week, Thinking Machines Lab (TML) released Interaction Models, introducing an architectural approach that takes direct aim at this problem. A surface-level comparison to existing systems like Gemini Live or OpenAI’s advanced voice models might make it look like another incremental step in real-time AI. But there’s more to it.
My Turn - Your Turn
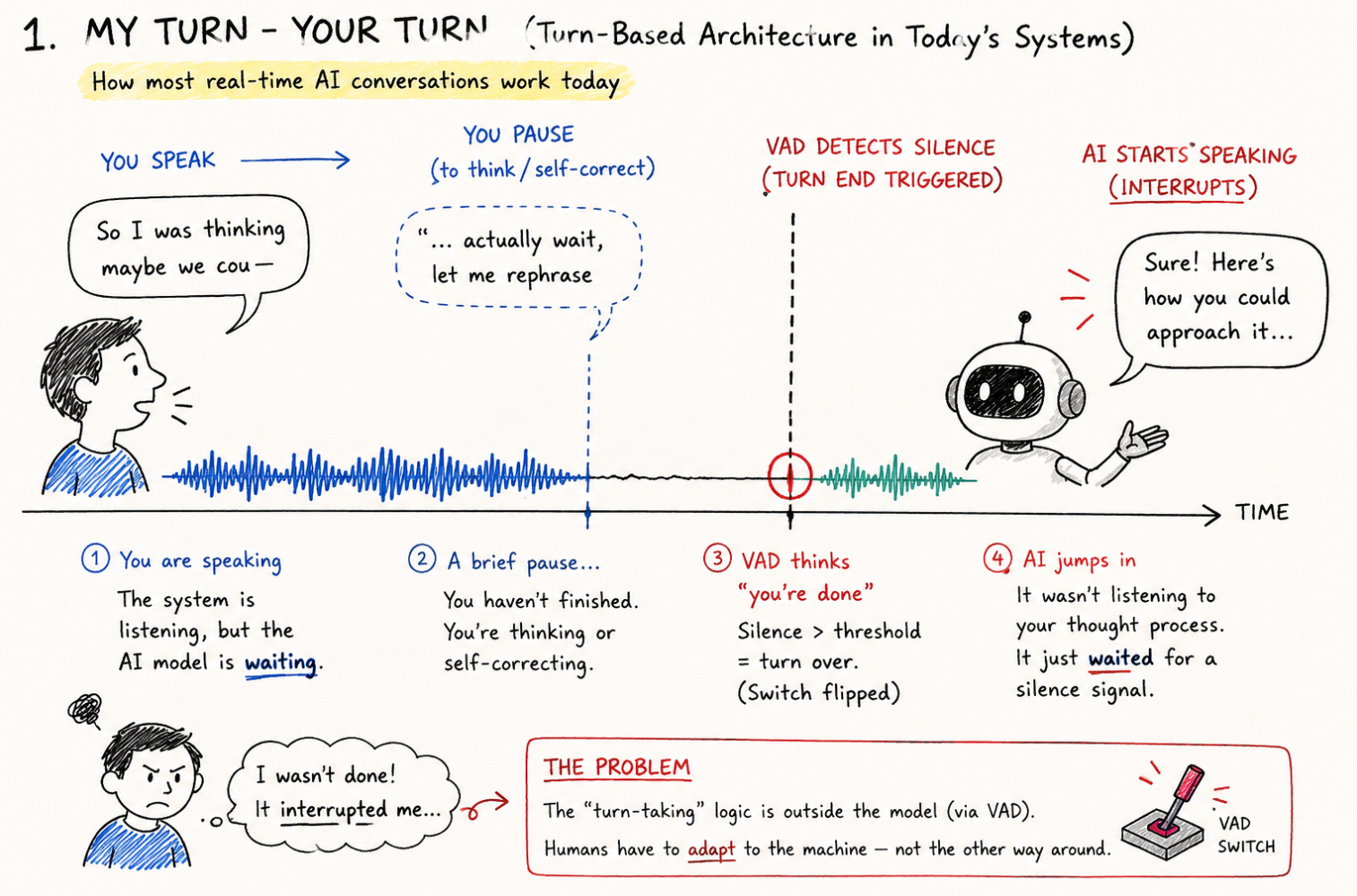
When using most of today’s real-time frontier models, the conversation feels fluid. Under the hood, however, these systems typically rely on a “turn-based” architecture. To simulate real-time interaction, developers attach external harnesses, specifically Voice Activity Detection (VAD) components, to manage the dialogue.
Think of VAD like an automated switch. When you speak, the core AI model is effectively waiting for you to finish; it has no perception of the ongoing audio. If the VAD harness detects a predefined moment of silence, it assumes your turn is over, stops listening, and triggers the model to respond. While this creates the appearance of real-time conversation, it is inherently brittle. A user who pauses to think, stumbles over a word, or self-corrects mid-sentence can inadvertently trip the switch, forcing humans to adapt their natural speaking patterns to fit the system’s constraints, rather than the other way around.
TML’s Native Interactivity
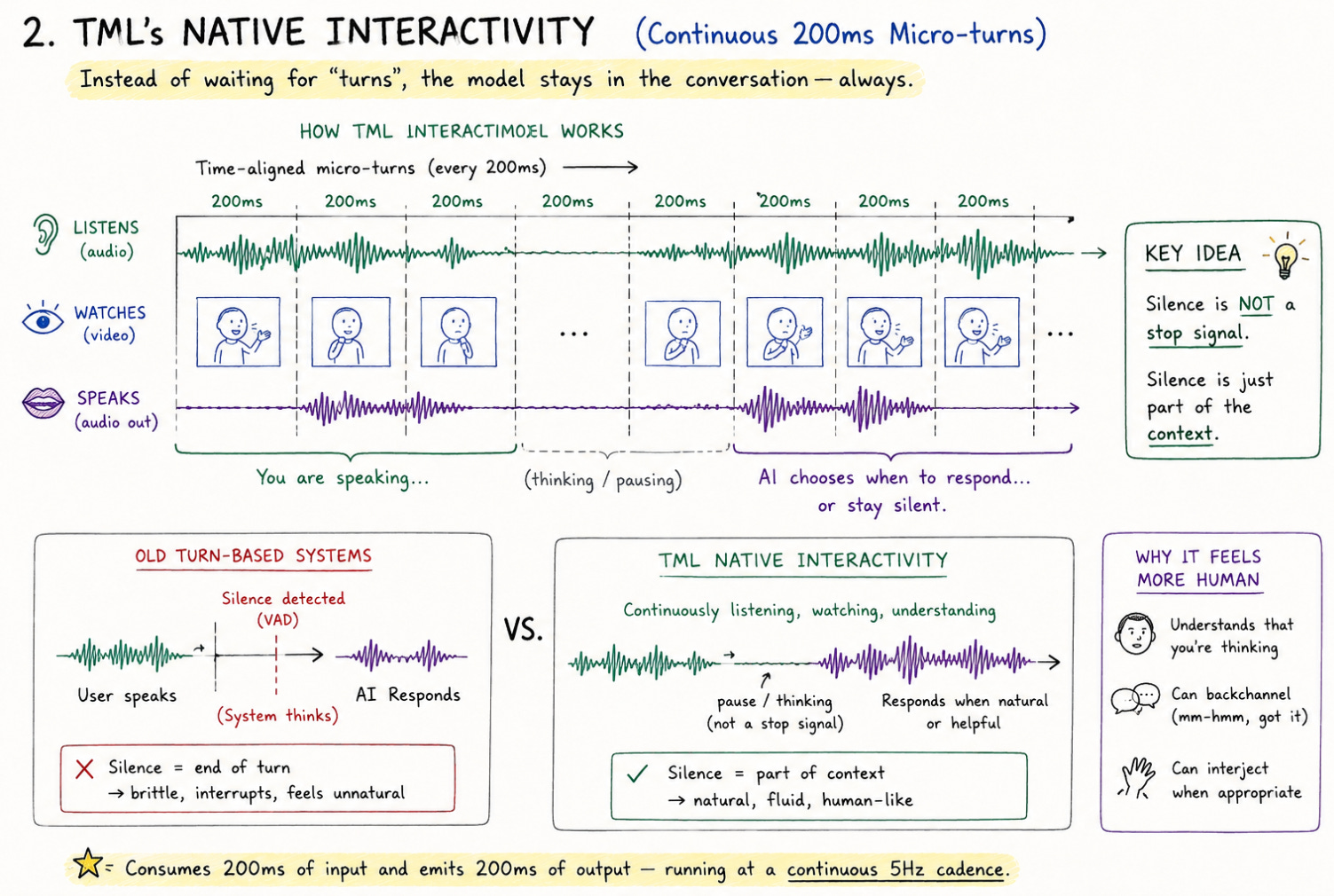
What TML implemented is a system where interactivity is built into the core model itself, rather than bolted on around it.
Instead of waiting for a predefined “turn” to end, TML’s Interaction Model processes data continuously through time-aligned micro-turns. It consumes 200 milliseconds of input and emits 200 milliseconds of output, running at a continuous 5 Hz cadence.
This is made possible through “encoder-free early fusion”. Rather than using separate transcription software to first convert speech into text, the model directly processes raw audio waveforms and raw video patches (small sections) into its neural network. It is absorbing reality as a continuous stream, which means it can simultaneously listen, watch, and speak.
In this framework, silence is no longer a trigger to stop, it is simply part of the context. The model tracks whether a user is thinking, yielding the floor, or self-correcting, and can stay silent, offer a backchannel response, or interject accordingly.
Fast or Intelligent or Cheap
This continuous processing introduces its own engineering challenge. Evaluating the world and generating a response every 200 milliseconds demands a model that is highly optimized and relatively small. This runs directly into a well-known constraint in AI systems design: fast, intelligent, and cheap are difficult to achieve simultaneously. Scale up the model’s reasoning capability, and it becomes too slow for real-time response. Optimize for speed, and you sacrifice depth.
TML’s answer is a Split Architecture, building on prior open-source work like Kyutai’s Moshi, which demonstrated how separating presence from intelligence could resolve the tension:
The Interaction Model is the fast, natively multimodal component operating in the 200ms loop. It handles real-time presence, manages conversation flow, and processes continuous audio-visual input.
The Background Model is a larger, asynchronous system that handles complex reasoning, planning, and tool use. When a user asks something that requires deeper thought, the Interaction Model silently delegates the work to this second model.
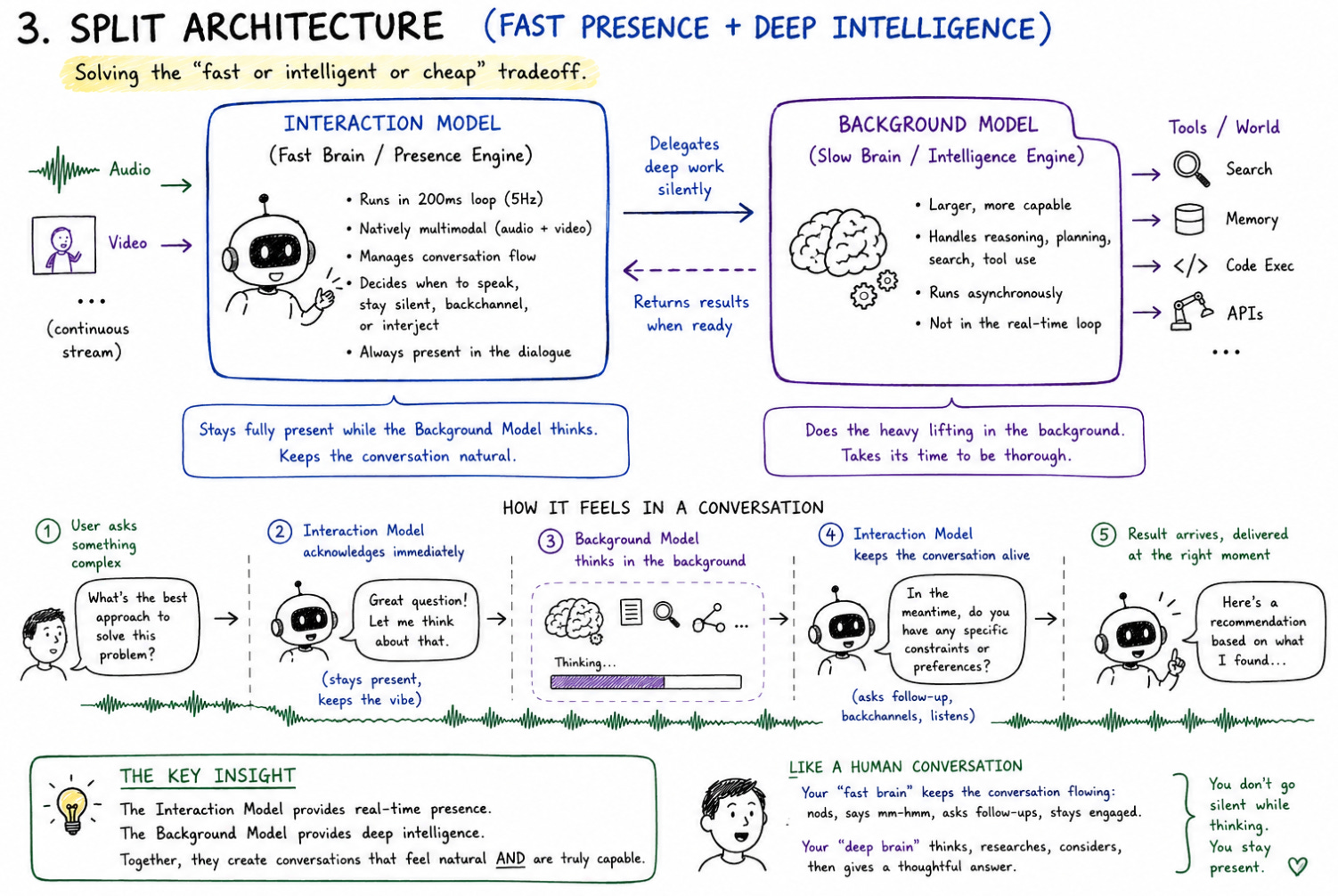
The key insight in this division is what happens during that delegation. While the Background Model works, the Interaction Model doesn’t freeze or fall silent, it stays fully present in the conversation. Once the Background Model returns its results, the Interaction Model weaves them into the dialogue at a natural moment, avoiding the jarring context switch that characterizes most AI assistants today.