

How batch size affects token cost and speed
batch sizes, empty seats, and the economics of speed

I’m sure you’ve noticed this if you use AI tools frequently. Companies like OpenAI, Cursor, and Anthropic have started offering a “Fast Mode,” where you can pay significantly more, sometimes 6x the price, to get your text generated at lightning speed. On the flip side, some platforms offer “Slow Mode,” where you get incredibly cheap rates if you’re willing to wait a few minutes for your answer.
I used to wonder: how exactly does throwing money at an AI make it think faster? Can you jus bribe the computer?
To understand this, we have to revisit our old friends from previous articles (Roofline Model, Speculative Decoding, KV Cache): the Master Chef (your processor) and the slow Waiter (your memory bandwidth). It all comes down to the mechanics of inference, and one deceptively simple concept called Batch Size.
The Master Chef’s Dilemma
Consider the following scenario. You ask ChatGPT a question. To generate the very first word of the answer, the system has to load the entire massive “brain” of the AI, hundreds of billions of weights, from memory into the processor.
In our restaurant analogy, this is like the slow Waiter hauling the entire pantry out to the Master Chef just so the Chef can chop a single carrot. As soon as that one word is generated, the whole process repeats.
If the AI company were serving only you, a single user, the economics would be brutal. The GPU would spend almost all of its time waiting for weights to be shuffled around, and almost none of it actually computing. The cost per word would be staggering.
The 20-Millisecond Train
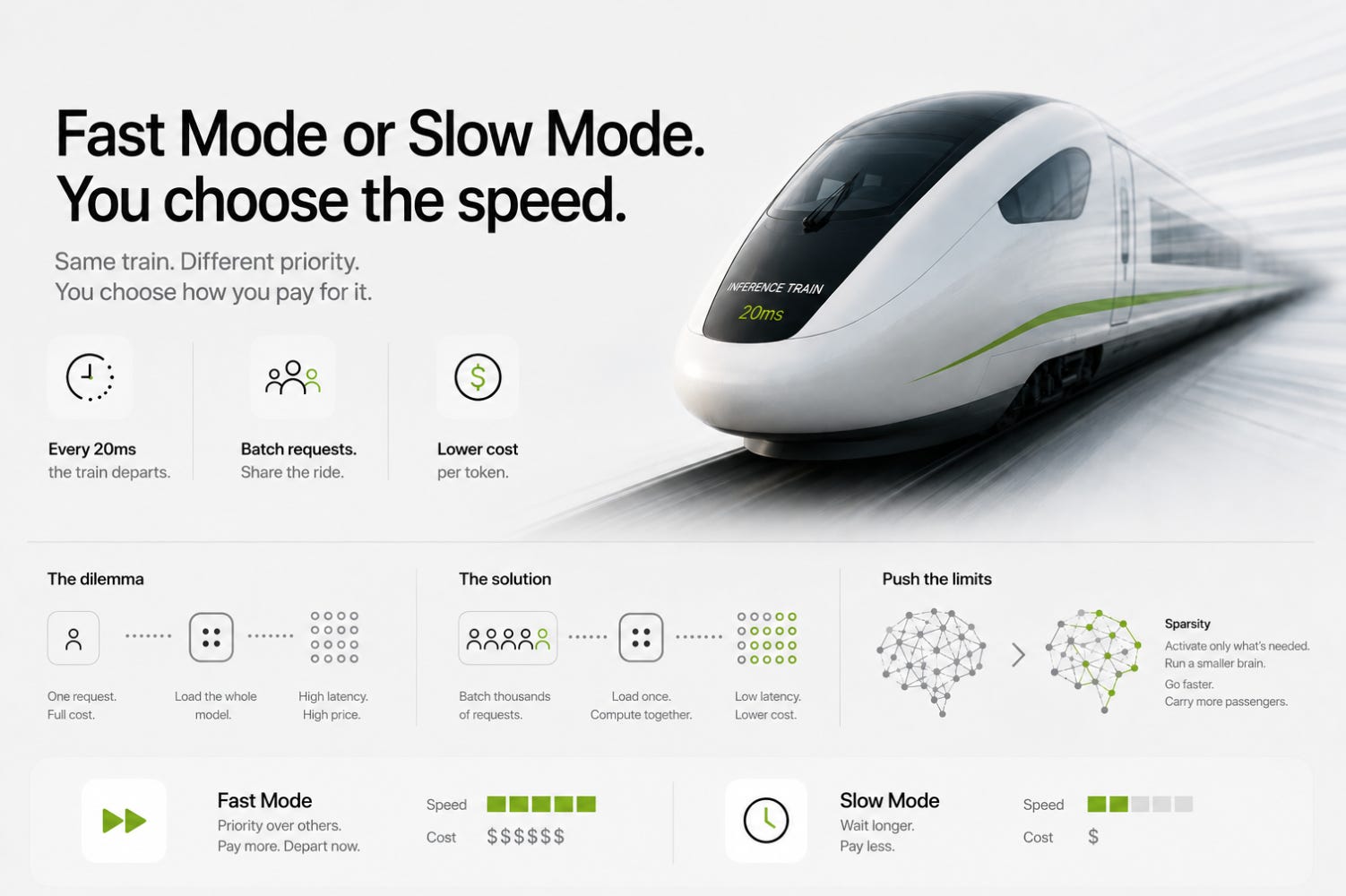
Here’s the thing: AI models don’t serve one person at a time. They serve thousands simultaneously. This is called Batching, and a train station is the cleanest way to picture it.
Deep inside the GPU, there’s a rigid, mathematical schedule. A new “inference train” departs every 20 milliseconds, with no exceptions. That 20-millisecond window is roughly the minimum time it physically takes to read all the model’s weights from High Bandwidth Memory into the chip. When the doors open, every user who has submitted a request hops on. The AI then calculates the next word for everyone on the train simultaneously.
If 2,000 passengers board, the GPU is packed. The Waiter still hauls out the entire pantry, but now the Chef is chopping 2,000 carrots at once. The cost of loading all those weights gets divided 2,000 ways, and the cost per token drops dramatically.
But if it’s 3:00 AM and only one passenger shows up? The train still departs. The weights still have to be loaded. The latency for that single user doesn’t improve, but the AI company has just run a full train for one ticket.
The Cost vs. Speed Trade-off
This is exactly why API pricing works the way it does.
“Fast Mode” is a VIP pass. You’re paying to force the train to depart even when it’s nearly empty. You get the minimum possible latency, close to the physical speed limit of the memory hardware, but you’re paying a premium because the provider isn’t filling their seats.
“Slow Mode” inverts this. The provider holds your request in the terminal, waiting until they’ve gathered enough passengers to fill the train. Because your patience enables near-perfect efficiency, they pass the savings on to you.
The speed of the hardware hasn’t changed in either case. What you’re actually buying is priority over other passengers.
Pushing the Limits with Sparsity
You might wonder - why stop at 2,000 passengers? Why not batch 100,000 requests and make the cost nearly zero?
Two things break down as batch size grows:
The Chef gets overwhelmed - More users mean more computation per cycle. At some point, the GPU becomes compute-bound rather than memory-bound, and adding more passengers actually slows the train down.
Memory fills up - Every user on the train brings their own luggage: the KV Cache, which stores the context of everything said so far in that conversation. With 100,000 passengers, the luggage compartment overflows.
Engineers address this with a technique called Sparsity (used in Mixture-of-Experts models). Instead of lighting up the entire neural network for every token, the AI activates only the fraction of its “brain” relevant to the current topic, sometimes as little as 1/8th of its parameters. A smaller active network means the Chef can work faster, the train can carry more passengers without slowing down, and the economics improve again.
That’s how the inference process is optimized for both the company and the user.
With that, it’s a wrap for today. I hope you enjoyed reading the article, understood it, and before I say goodbye for today, here’s a quote I’ve been pondering,
"All really great things are happening in slow and inconspicuous ways."
If you’ve made it this far, please don’t forget to share it with your friends, family, and strangers.
Have a Great Day 💖