

MoE Parallelism
how modern AI models split the work

Time for another rabbit hole. By now, you are well acquainted with our old friend, the Master Chef (your processor). We’ve watched this chef furiously chop potatoes while waiting on a slow waiter, and we’ve even given them a tiny Sous-Chef to help guess the next orders.
But today, we need to talk about what happens when the restaurant gets too big.
In recent years, AI models have grown so massive that they simply cannot fit inside the memory of a single GPU. To solve this, researchers had to figure out how to split the AI’s “brain” across multiple processors. And to understand how they do it, especially with a clever technique called Expert Parallelism → we first need to look at how modern AI models are structured.
Too Many Dishes, One Kitchen
In a traditional, “dense” AI model, every single word (or token) that passes through the system is processed by the exact same massive neural network layer. Think of this as having one Master Chef who cooks every single item on a 10,000-item menu.
But newer models, like Mistral’s Mixtral 8x7B, use an architecture called Mixture of Experts (MoE). Instead of one giant, generalized layer, the model contains multiple parallel, specialized layers - the “experts.”
When a new token arrives, a routing layer acts like the restaurant manager. It looks at the incoming word, decides which experts are best suited to handle it, and sends the token only to those experts.
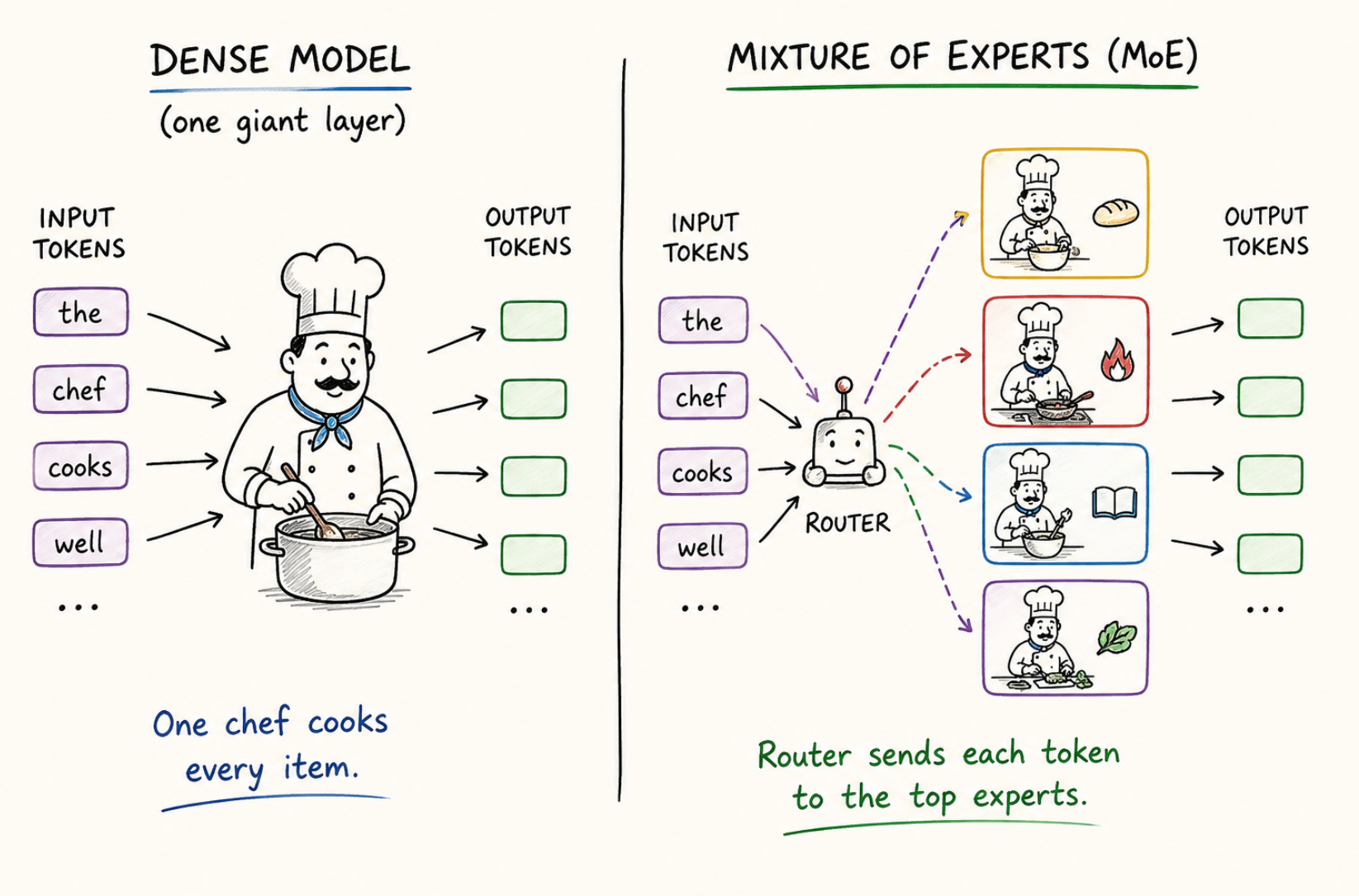
And here’s the clever part: even if the model contains dozens or hundreds of experts, each token usually activates only a tiny subset of them, often just two. So the model gains enormous capacity without having to run every expert for every token.
It’s like having an entire building full of specialist chefs, but only calling in the two most relevant ones for each order.
This is incredibly efficient. But because these MoE models are still gigantic, engineers need to spread this team of experts across multiple GPUs.
And there are a few different ways to do that.
Method 1: Tensor Parallelism
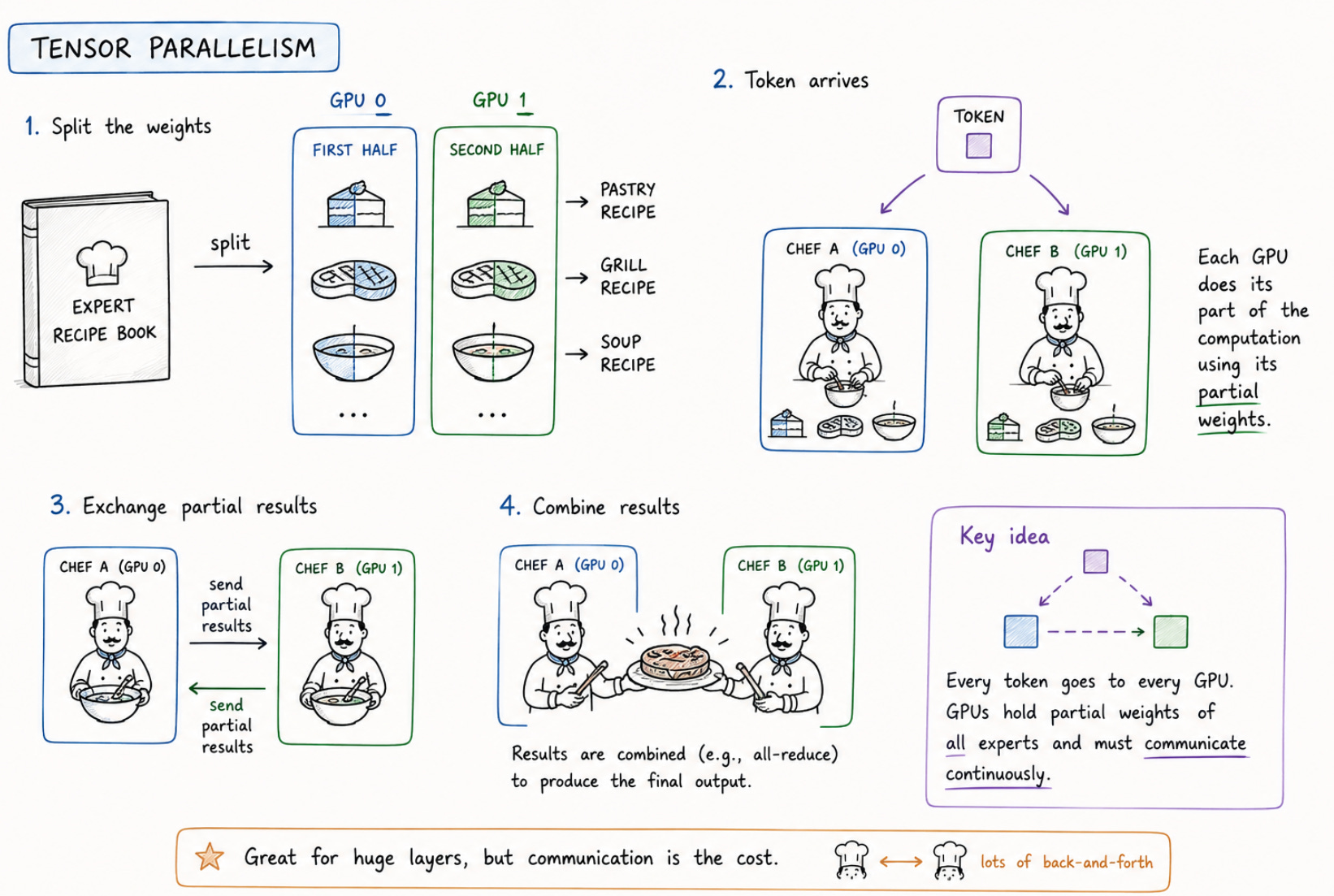
One of the most common ways engineers split large AI models is called Tensor Parallelism.
And it works in a surprisingly mechanical way.
Instead of giving one GPU a complete expert, engineers split the expert’s weights, the model’s learned knowledge into pieces and distribute those pieces across multiple GPUs.
In our restaurant analogy, Chef A gets the first half of the pastry recipe, the grill recipe, and the soup recipe. Chef B gets the second half of all those same recipes.
Now, because every GPU holds only part of each expert’s knowledge, the GPUs must work together every time a token arrives. Each GPU performs its portion of the computation, and then the results are combined together.
So instead of one chef preparing a full dish, several chefs each prepare fragments of it simultaneously and constantly pass partially completed dishes back and forth.
This works extremely well for very large layers, but it comes with a cost: the GPUs need to communicate with each other continuously.
Method 2: Expert Parallelism
This brings us to a more specialized approach: Expert Parallelism.
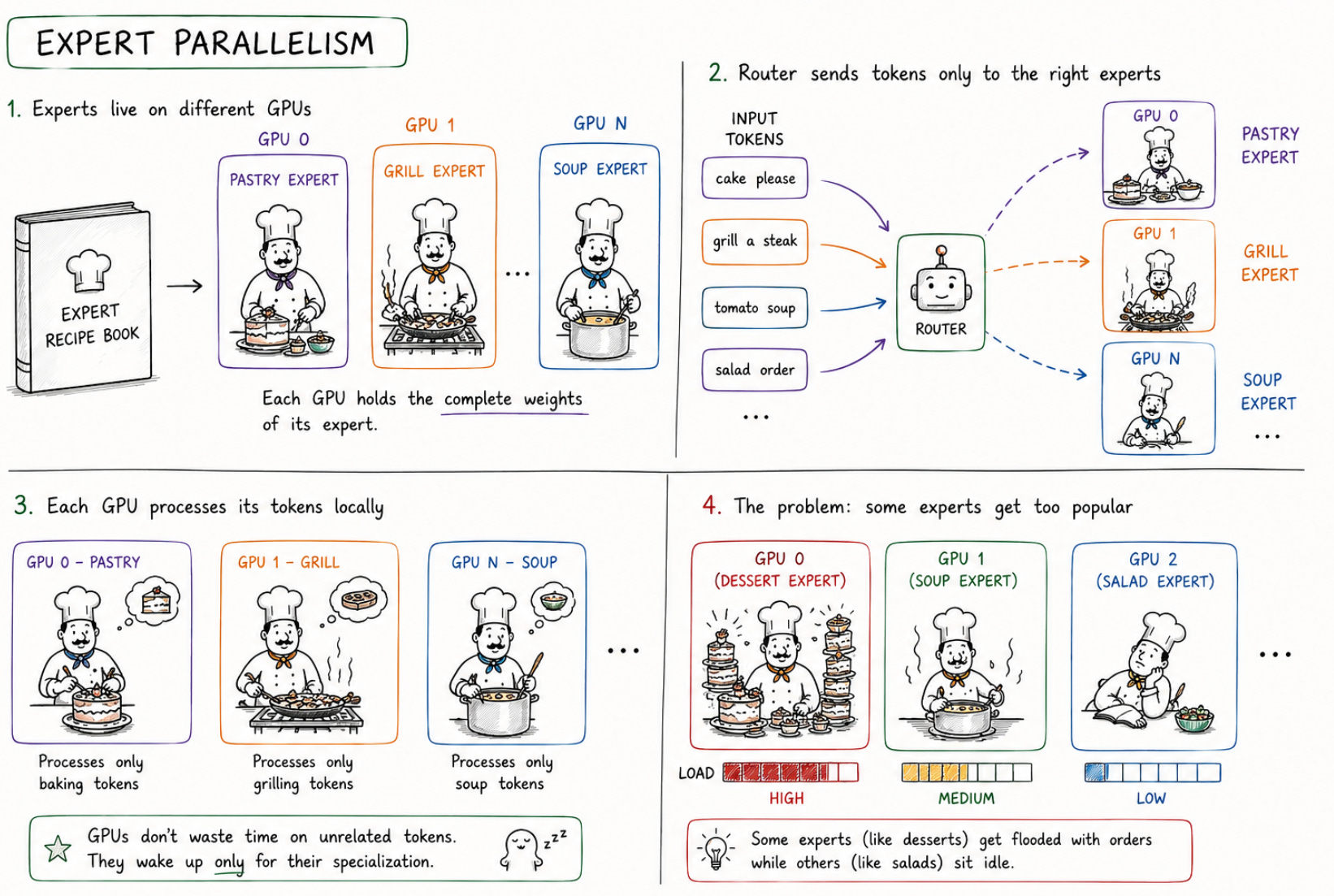
Instead of splitting every recipe into pieces, engineers let entire experts live on specific GPUs.
Chef A gets the entire pastry station.
Chef B gets the entire grill station.
Now the router no longer needs to send every token to every GPU. It only sends pastry-related tokens to the pastry expert, grilling-related tokens to the grill expert, and so on.
Each GPU receives only the tokens meant for its experts and processes them using the complete weights stored locally.
This avoids a huge amount of unnecessary computation. GPUs no longer participate in every token’s processing, they only wake up when their specialization is needed.
But this introduces a new problem.
Some experts become much more popular than others.
Maybe the coding expert suddenly gets flooded with programming questions while the poetry expert sits idle. One GPU becomes overwhelmed while others stay underutilized.
So engineers needed another trick.
Combining Both Approaches
What if a single expert is still too large for one GPU to hold?
Or what if one expert becomes so heavily used that a single GPU can’t keep up?
This is where engineers combine both strategies into a Hybrid Parallel setup.
First, they assign a specific expert to a small group of GPUs using Expert Parallelism. Then, inside that expert, they split the weights across those GPUs using Tensor Parallelism.
So now the pastry station is handled by Chef A and Chef B together.
Chef A holds the first half of the pastry recipe.
Chef B holds the second half.
When a pastry order arrives, the token is sent to both chefs simultaneously, and they work together to complete just that specific task.
This gives engineers the best of both worlds:
Expert Parallelism decides which GPUs own which experts
Tensor Parallelism decides how those experts internally split the work
This balancing act allows extremely large models to scale efficiently without overloading a single GPU.
When One Expert Gets Too Popular
But what if the restaurant suddenly gets flooded with pastry orders?
Even if Chef A and Chef B are working together at the pastry station, they can still become overwhelmed while the grill station sits mostly idle.
To solve this, engineers sometimes scale horizontally using Data Parallelism (often called Expert Replication in MoE systems).
Instead of splitting the pastry expert further, they simply create another identical pastry station somewhere else in the restaurant.
They copy the entire pastry expert - including all its weights onto another set of GPUs.
Now, when ten pastry orders arrive at once, the router can distribute the workload between both pastry stations.
Unlike Tensor Parallelism, this approach does not split the recipe into pieces. It duplicates the entire station so multiple identical teams can handle requests simultaneously.
This is especially useful during inference, where some experts may suddenly become extremely popular depending on what users are asking.
Modern AI systems are no longer just one giant neural network running on one giant machine.
They are carefully coordinated systems of specialists:
routers deciding where tokens should go
experts specializing in different patterns
GPUs collaborating on shared computations
and entire expert stations duplicating themselves when demand becomes too high
All of it working together to generate the next word in a sentence.